AmebaPro2 集成了专用的 NPU (神经网络处理单元),在 INT8 精度下可提供高达约 0.4 TOPS 的算力,从而加速边缘端 (Edge) 的深度神经网络推理。
 神经网络 (NN) 工作流程
神经网络 (NN) 工作流程
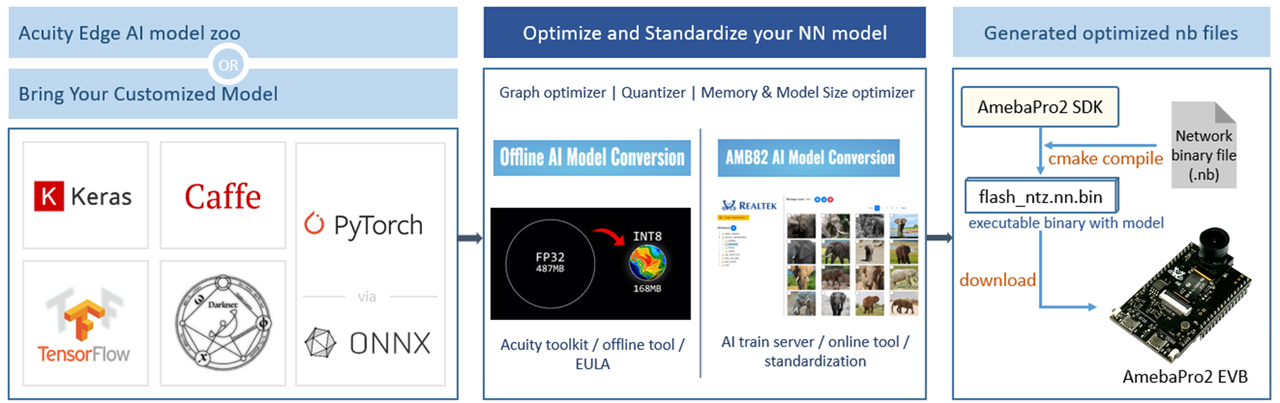
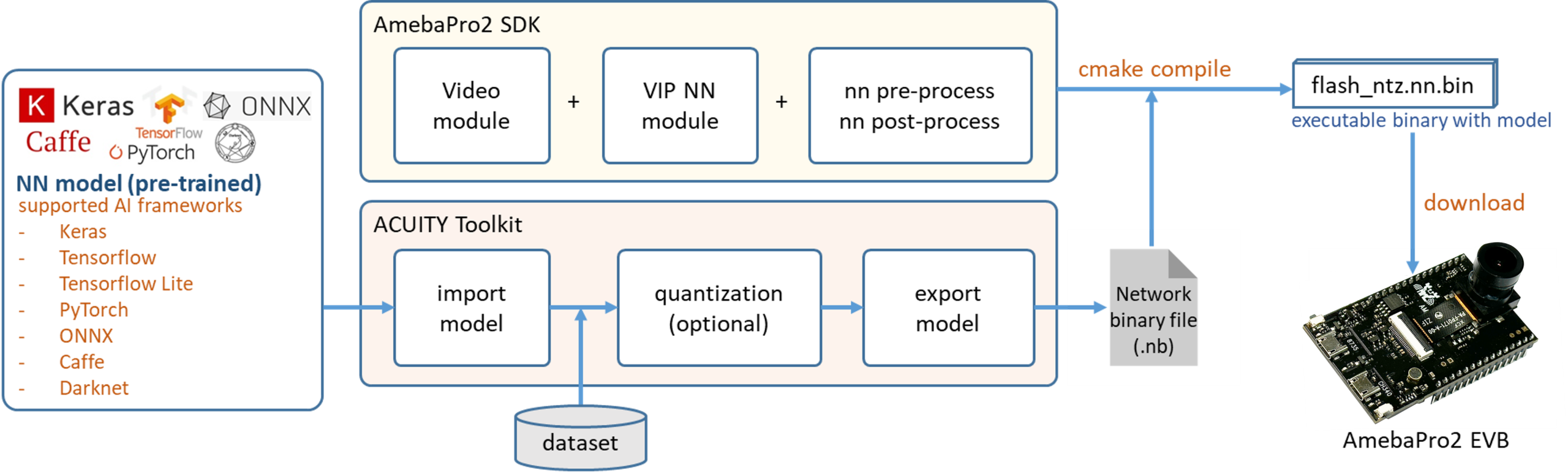
神经网络的工作流程始于使用 Acuity Toolkit 进行模型转换。
- 支持框架:可将来自 TensorFlow、PyTorch、ONNX、Caffe、Keras 和 Darknet 等主流框架的预训练模型进行转换。
- 输出格式:转换为优化的 .nb (network binary) 文件。
- 量化支持:支持 INT8、INT16 (DFP) 以及 FP16 量化技术。
运行时 (Runtime) 处理
在运行时,vipnn MMFv2 模块会执行以下步骤:
 图像捕获:从 ISP 摄像头流水线 (camera pipeline) 捕获 RGB 视频帧。
图像捕获:从 ISP 摄像头流水线 (camera pipeline) 捕获 RGB 视频帧。 预处理:进行图像缩放 (resize) 和格式转换。
预处理:进行图像缩放 (resize) 和格式转换。 NPU 推理:通过 VIPLite 驱动程序将张量 (tensor) 数据发送至 NPU 进行推理。
NPU 推理:通过 VIPLite 驱动程序将张量 (tensor) 数据发送至 NPU 进行推理。 后处理:运行针对特定模型的后处理操作 (例如:边界框解码、非极大值抑制 NMS),以生成结构化的目标检测或分类结果。
后处理:运行针对特定模型的后处理操作 (例如:边界框解码、非极大值抑制 NMS),以生成结构化的目标检测或分类结果。
模块化架构优势
该模块化架构具有极高的灵活性与安全性,支持以下功能:
 即插即用 (Plug-and-play) 的模型集成
即插即用 (Plug-and-play) 的模型集成- 零拷贝 (Zero-copy) 缓冲区优化
- 级联式多模型流水线 (Cascaded multi-model pipelines)
 可选的模型安全功能:包括 Ed25519 签名验证与 AES-CBC 加密技术
可选的模型安全功能:包括 Ed25519 签名验证与 AES-CBC 加密技术